AIに必要なのは「記憶の量」ではなく「記憶の質」である
Cursor、Claude Code、Mem0、Pieces、Graphiti, そして新たに生まれつつあるカテゴリ「Decision Memory」を比較する。
AIコーディングのエコシステムは、いま急速に一つの共通したアイデアへと収束しつつあります。それは「記憶(メモリ)」です。
Cursor、Claude Code、Mem0、Pieces、そして数多くの新興のAIエージェントフレームワークは、いずれも同じ根本的な課題に向き合っています。ソフトウェアプロジェクトは何年も生き続ける一方で、AIアシスタントの寿命は数分です。新しいセッションが始まるたびにAIは部分的な記憶喪失の状態にあり、開発者もエージェントも、すでに分かっていたはずの文脈を何度も探し直すことになります。
業界の最初の答えは単純でした。「もっと多くの情報を保存する」とのことです。会話履歴、コードスニペット、ドキュメント、タイムライン、ブラウザの操作履歴、ワークフローの記録——これらはいずれも、放っておけば失われてしまう知識を保存するのに役立ちます。
生まれつつあるAIメモリシステムの全体像を研究するうちに、気づきました:様々なメモリシステムが、それぞれ異なる問題を解こうとしているのです。
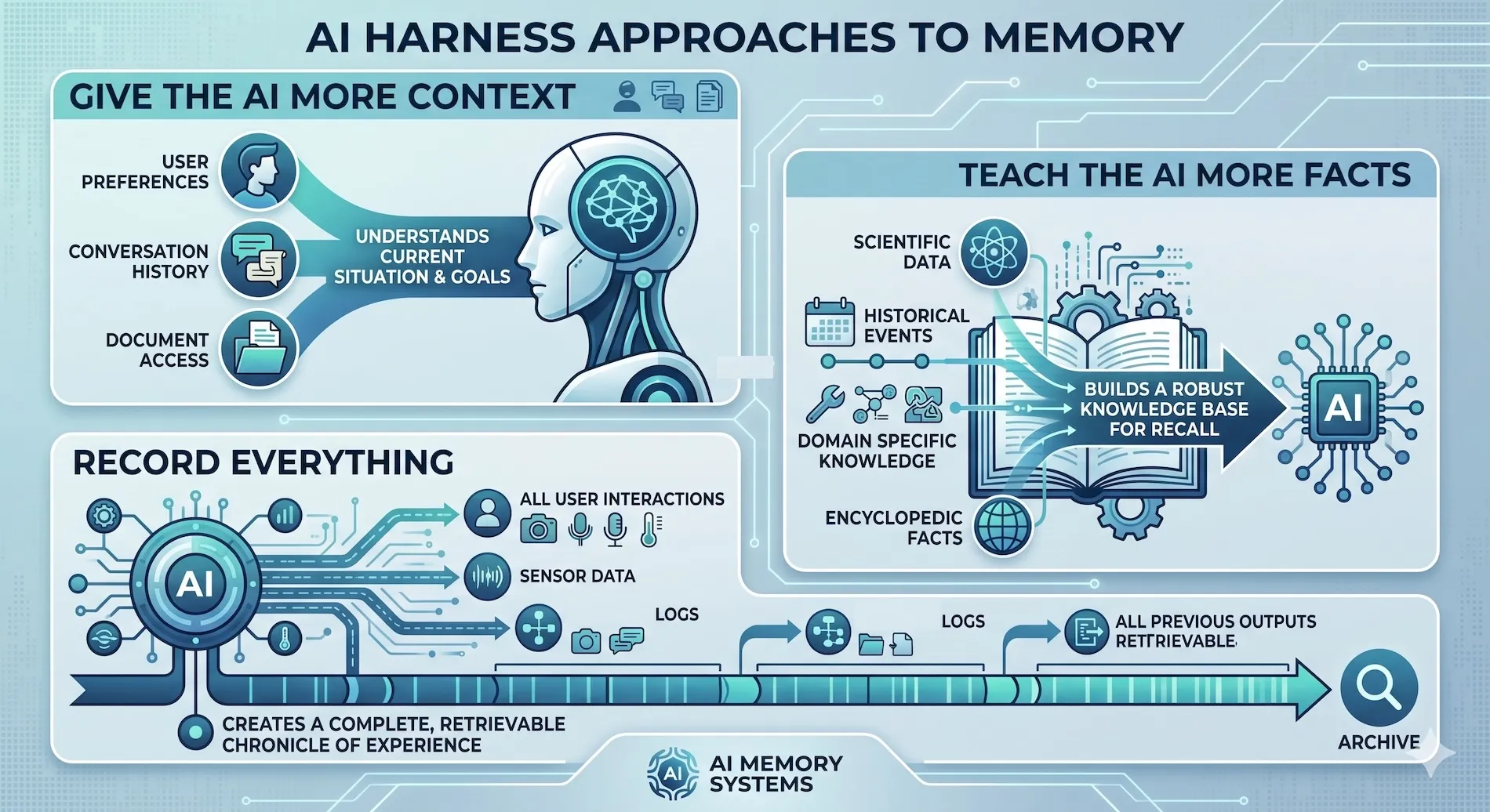
今日のAIメモリ、3つのアプローチ
この分野の製品の多くは、3つのカテゴリに分類できます。
1. AIにもっと多くコンテキストを与える
GitHub Copilot、Cursor、Claude Code、Windsurf などは、主にAIに出来るだけ多くのコンテキストを与えることを重視しています。カスタムインストラクション、ルール、チャット履歴、プロジェクトファイル、ドキュメント、検索で取得したスニペットなどを組み合わせ、大きなコンテキストウィンドウを構成します。
短〜中規模のタスクでは、これは十分に効果的です。モデルはかなりの量の情報を踏まえて推論し、セッションを通じて勢いを保つことができます。しかし、プロジェクトが成長するにつれて、新たな課題が見えてきます。
情報が蓄積するもので、本当に重要な情報を見極めることが難しくなります。情報は存在しているのに、人間もAIも、いま取り組んでいるタスクにとってどの部分が重要で、どの部分がもはや無関連なのかを判断しづらくなります。チームはこの現象を「コンテキストブロート(context bloat)」と呼びます。
興味深いことにこのカテゴリ自身も既に「コンテキストだけでは足りない」という課題をCursorが直面していました。Cursor は2025年に、会話から得た事実を自動的に保存するプロジェクト単位の「Memories」機能を投入しましたが、その後この機能を取り下げ、ユーザーを手書きの Rules へと再び誘導しました。事実を蓄積するだけでは、問題は解決しなかったのです。
2. AIにより多くの事実を教える
Mem0 のようなメモリレイヤーや、Letta(旧 MemGPT)のようなエージェントランタイム、そして RAG ベースのフレームワークは、会話やインタラクションから事実・要約・エンティティ・関係性を抽出することを重視します。会話全体を保存するのではなく、記憶しておく価値のある持続的な情報、アーキテクチャ上の事実、ユーザーの好み、さらには長期的なエージェントの知識などを見極めようとします。
メモリが検索可能で構造化されたものになるため、これは単純な会話履歴に比べて大きな前進です。システムは「何を知っているか」にはうまく答えられるようになりますが、「なぜそう決めたのか」に答えられるとは限りません。その判断に至るまでの経緯や背景にあった制約・トレードオフまでは記録されません。記憶の基本単位は以前として事実や要約、関連性であり、その背後にある意思決定や推論の過程ではありません。
ソフトウェアエンジニアリングにおいて、これはドキュメント、APIリファレンス、設計文書、ランブックなどには驚くほど上手く機能します。しかし、その知識がどのように変化してきたのか、その背後にある「理由」などの洞察みたいなものがまだまだ難しい課題です。
このカテゴリの最も先進的なシステムは、さらにその先を行きます。たとえば Zep の Graphiti は、知識を時間軸を持つナレッジグラフ(temporal knowledge graph)として保存し、すべての事実に「いつ真になり、いつ無効化されたか」という有効期間を持たせます。これは実に強力で、フラットなベクターストアよりも、プロジェクトが実際に変化していく様子にずっと近いものです。しかし、記憶の単位は依然として「事実」です。時間軸を持つグラフは、「我々は RabbitMQ を使っている」が3月に真となり5月に置き換えられた、と記録できます。しかし、Kafka と SQS が代替案だったこと、決め手となった制約が小規模なプラットフォームチームだったこと、そしてその変更が偶発的なドリフトではなく意図的なトレードオフだったことは記録できません。推論そのものは、決してグラフには入らないのです。
ここで、ご閲覧いただいているこのサイトを作る中で下した、意思決定を見てみましょう。
事実はこうです:ソーシャルカード画像は IBM Plex Sans JP フォントを使っている。
意思決定はこうです:
日本語のソーシャルカード画像には Noto Sans JP ではなく IBM Plex Sans JP を使う。
検討した代替案: Noto Sans JP, Noto Sans CJK JP
理由: Fontsource が配信する Noto Sans JP はバリアブルフォントで、ビルド時のレンダラー
(CanvasKit)はこれを "Noto Sans JP Thin" というファミリー名で登録する。こちらの
フォント指定リストはこの名前と一致しないため、日本語のカードがすべて空白の
「豆腐(tofu)」になってしまった。IBM Plex Sans JP は固定ウェイトで、ファミリー名
も安定している。
制約: CanvasKit はリストに明示的に指定されたフォントの間でしかフォールバックしない。
日付: 2026年6月実際にリリースされるコードに残るのは 'IBM Plex Sans JP' という記述だけです。上記の理由は、どこにも残りません。後になってあるAIエージェントが「ブランドの統一のために Noto フォントを使って」と指示されれば、それを元に戻し、豆腐(tofu)のバグを再発させてしまうでしょう——そしてその選択が意図的なものだったことを、知るすべがありません。事実はコードの中にありますが、意思決定はそこにはないのです。
3. すべてを記録する
Pieces は異なるアプローチを取ります。会話やコードだけに注目するのではなく、ソフトウェア開発を取り巻くより広いワークフローを捉えます。コードの編集、コピーしたスニペット、閲覧したWebサイト、AIとの会話、デスクトップの操作、開発履歴などが、検索可能なタイムラインの一部になります。
これは、エピソード記憶とも言うべき、非常に印象的な形の記憶を生み出します。
開発者は、昨日・先週・先月に何が起きたのかを、自分の記憶だけに頼るよりもはるかに正確に再構成できます。Pieces がとりわけうまく答えてくれる問いは、「自分は何をしていたか」とのことです。
ソフトウェアプロジェクトを最終的に形づくるのは、活動そのものではなく意思決定です。会議の要約を知ることは有用ですが、AIエージェントがなぜ特定選択肢を選んだのかをその場で知れることのほうが、大きな価値があります。プロジェクトの現在の状態は、何千もの意思決定の最終的なスナップショットにすぎません。それらの意思決定がどのように進化してきたのかを理解しないかぎり、人間もAIエージェントも、同じ推論を何度も繰り返すことになります。
欠けているレイヤー:Decision Memory
長期間運用されているソフトウェアプロジェクトを分析したところ、大きな問題の原因が、ドキュメント不足や貧弱なナレッジグラフに起因することは意外な程少ないと分かりました。むしろ、バグや不具合は「忘れられた意思決定」から生まれます。
新しいエンジニアが、数か月前にすでに却下された設計について議論を蒸し返す。AIエージェントが、以前に却下された解決策を再び実装してしまう。あるいは、目の前の「事実」と周辺のコードだけを分析し、表面的な修正を加えようとする。実際には、2週間前に別のエージェントが、同じ問題に取り組み、多くの課題を解決するためのユーティリティをすでに実装していたにも関わらず、その経緯が共有されていなかつたのです。
その情報は、たいてい git の履歴、プルリクエスト、Issue トラッカー、Slack の会話、あるいはAIとのチャット履歴のどこかに、依然として残っています。問題は、意思決定そのものが管理の対象になっていないことなのです。
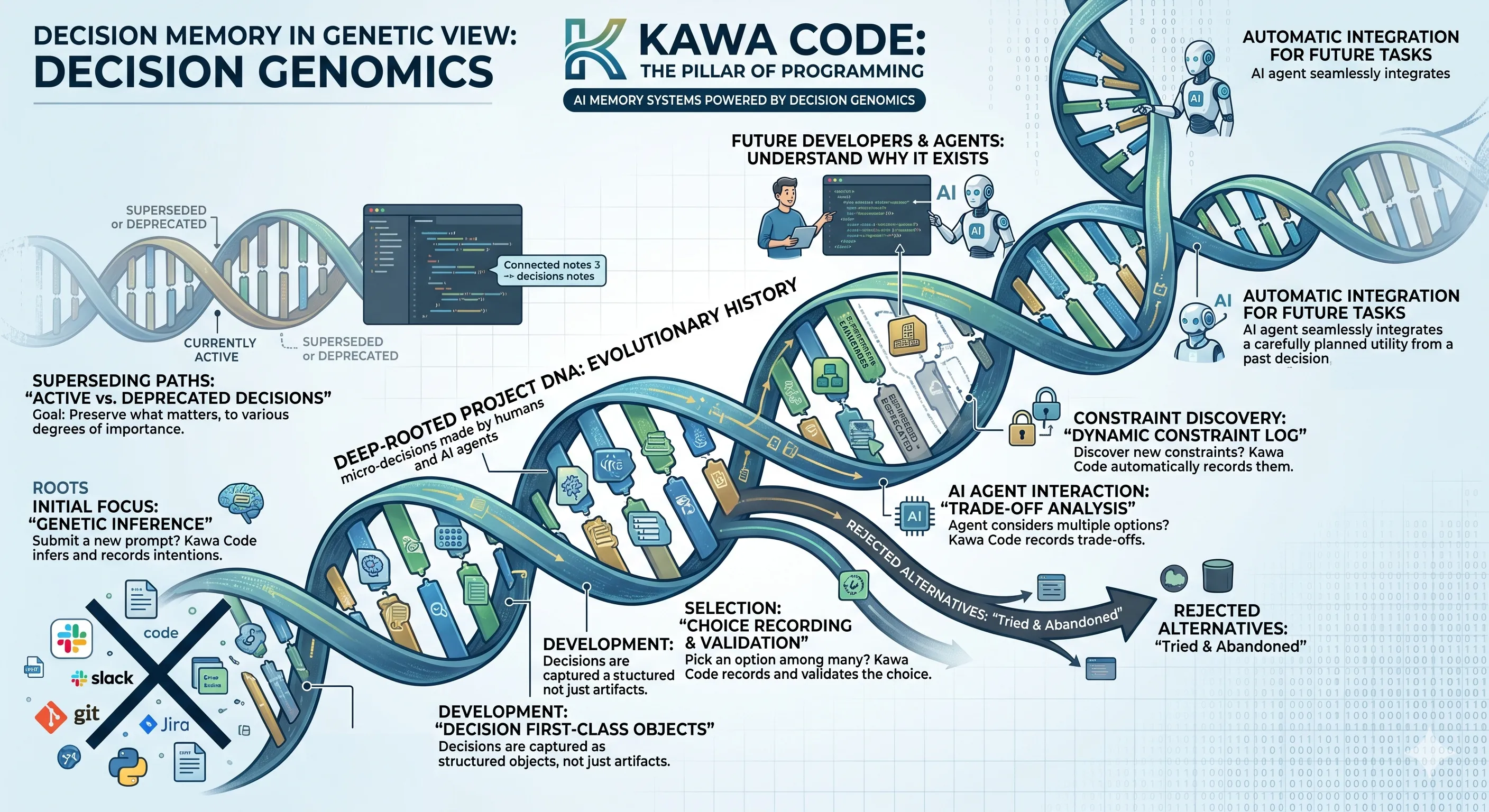
Kawa Code と Decision Genomics
AIコーディングのワークフローが成熟するにつれ、多くの組織が気付き始めていますが、情報を保存するのではなく、本当の課題は、どの情報をAIに渡すべきかを判断することです。
Kawa Codeは、私たちがソフトウェア開発において最も価値のある資産だと考えるものを中心に設計されています。それは、人間とAIエージェントが積み重ねてきた無数のマイクロ意思決定のグラフです。
Kawa Codeは、プロジェクトに関わる人間とAIエージェントの意思決定を自動的に抽出・構造化し、その変遷を追跡します。
- 新しいプロンプトを送信した? Kawa Code はその意図を推定し、記録します。
- 複数の選択肢から一つを選んだ? Kawa Code はその意思決定と判断の背景を記録します。
- エージェントが複数の選択肢を比較検討した? Kawa Code はそこで検討されたトレードオフを記録します。
- 新たな制約が見つかった? Kawa Code は将来のためにその制約を保存します。
- 試した結果、採用を見送った案がある? Kawa Code はそれを却下された代替案として記録します。
- AIとアーキテクチャについて議論した? Kawa Code はその意思決定の根拠を記録します。
これらの意思決定は、関連するコードに紐づけられたまま管理され、ブランチやリベースを経ても維持されます。また、プロジェクトの進化に合わせて更新され続けます。古くなった意思決定は、ベクターストア内の事実のようにいつまでも有効なコンテキストとして残り続けるのではなく、上位の意思決定に置き換えたり、役割を終えたものとして整理したりできます。目指しているのは、あらゆる情報を保存することではありません。本当に重要な情報を、その重要度に応じて管理し、AIエージェントが取り組むタスクごとに必要な情報を自動的に活用できるようにすることです。
これが Architectural Decision Records(ADR)や、Cline で広まったような手書きのマークダウン「メモリバンク」のように聞こえるなら、その違いは「捕捉(キャプチャ)」にあります。ADR やメモリバンクは手で書かれ、コードが先に進んだ瞬間に古くなり、そして説明対象のコードとは別の場所に置かれています。Kawa Code は、あなたとエージェントが作業する傍らでこれらの意思決定を自動的に捕捉し、それが支配するまさにその行に紐づけ、ブランチやリベースを越えて運びます——だから、誰も書き留めることを覚えておく必要はなく、それらがいつの間にか陳腐化することもありません。
私たちはこのアプローチを Decision Genomics と呼んでいます。DNA が生物の進化の歴史を保存するように、ディシジョングラフはソフトウェアプロジェクトの進化の歴史を保存します。未来の開発者やAIエージェントは、今日何が存在するのかだけでなく、なぜそれが存在するのかまで理解できるようになります。
今日のメモリの多くは、個人ごと、あるいはツールごとに分断されています。Cursor のメモリは Cursor の中にしか存在せず、同じマシンで Claude Code や別のエージェントを使っても共有されません。そして、先週発見したことを誰かが手で書き残さないかぎり、チームメイトのエディタにその知識が届くこともありません。Kawa Code はその逆です。ディシジョングラフは、人間とAIエージェントの間で、さらにエディタやツールの垣根を越えて共有されます。VS Code、JetBrains、Emacs、そして Claude Code、Cursor、Windsurf などの MCP 対応エージェントをまたいで利用できるため、ツールごとの個別のメモリではなく、チーム全体で共有される推論レイヤーとして機能します。
その推論は作業がまだ進行中の段階で共有されるため、Kawa Code は、二人のチームメイトがどちらもコミットする前に同じコードを変更していることを検知し、その重なりをエディタ上で直接示すこともできます——マージの後で衝突を発見するのではなく、マージの前に回避するのです。このコミット前のインターセクション検出は特許を取得しています(JP 7150002)。
| アプローチ | 代表例 | それが答える問い |
|---|---|---|
| AIにコンテキストを与える | Cursor、Claude Code、Windsurf | 「どの情報が重要になりうるか」 |
| AIに事実を教える | Mem0、Letta | 「何を知っているか」 |
| すべてを記録する | Pieces | 「自分は何をしていたか」 |
| WHY を記憶する | Kawa Code | 「なぜそう決めたのか」 |
これには重要な副次的効果があります。履歴全体ではなく、意思決定・制約・根拠に焦点を当てることで、Kawa Code はAIアシスタントに対して、しばしば劇的に小さなコンテキストを提供できます。何か月分もの会話やドキュメントを再生するのではなく、いまのタスクに最も関連する推論だけを抽出して示すのです。数十、あるいは数百のAIエージェントを運用する組織にとって、これは推論コストの低減とスループットの向上に直結し得ます。
AIの普及が進み、トークンコストが無視できない運用コストになっていく中で、私たちはAIメモリの未来が、想起(recall)の品質だけでなく、圧縮(compression)の品質——プロジェクトの背後にある推論をいかに保ちつつ、モデルに送る情報量をいかに最小化できるか——によっても測られるようになると考えています。
メモリのその先へ
AIを活用したソフトウェア開発における今後の課題は、おそらくコード生成ではありません。モデルはすでに、コードを書くことにかけては並外れて優秀になりつつあります。
より難しい問題は、人間とAIが数か月、あるいは数年にわたって下す何千もの意思決定の間で、一貫性を保ち続けることです。メモリシステムは、その未来の重要な一部です。
私たちは、次世代の開発ツールを定義するのは、プロジェクトをかたちづくる意思決定を、いかに効果的に捕捉し、進化させ、そして必要な場面で示せるかだと考えています。
より多くの記憶ではなく、より良い記憶を。