AI Doesn't Need More Memory. It Needs Better Memory.
Comparing Cursor, Claude Code, Mem0, Pieces, Graphiti, and the emerging category of Decision Memory.
The AI coding ecosystem is rapidly converging on a common idea: memory.
Tools such as Cursor, Claude Code, Mem0, Pieces, and many emerging AI agent frameworks all recognize the same fundamental problem. Software projects live for years, while AI assistants live for minutes. Every new session begins with partial amnesia, forcing developers and agents to repeatedly rediscover context that was already known.
The industry’s first response has been straightforward: store more information. Conversation history, code snippets, documentation, timelines, browser activity, workflow recordings, and vector databases all help preserve knowledge that would otherwise be lost.
As I looked at the emerging landscape of AI memory systems, I’ve noticed something interesting: not all memory systems are trying to solve the same problem.
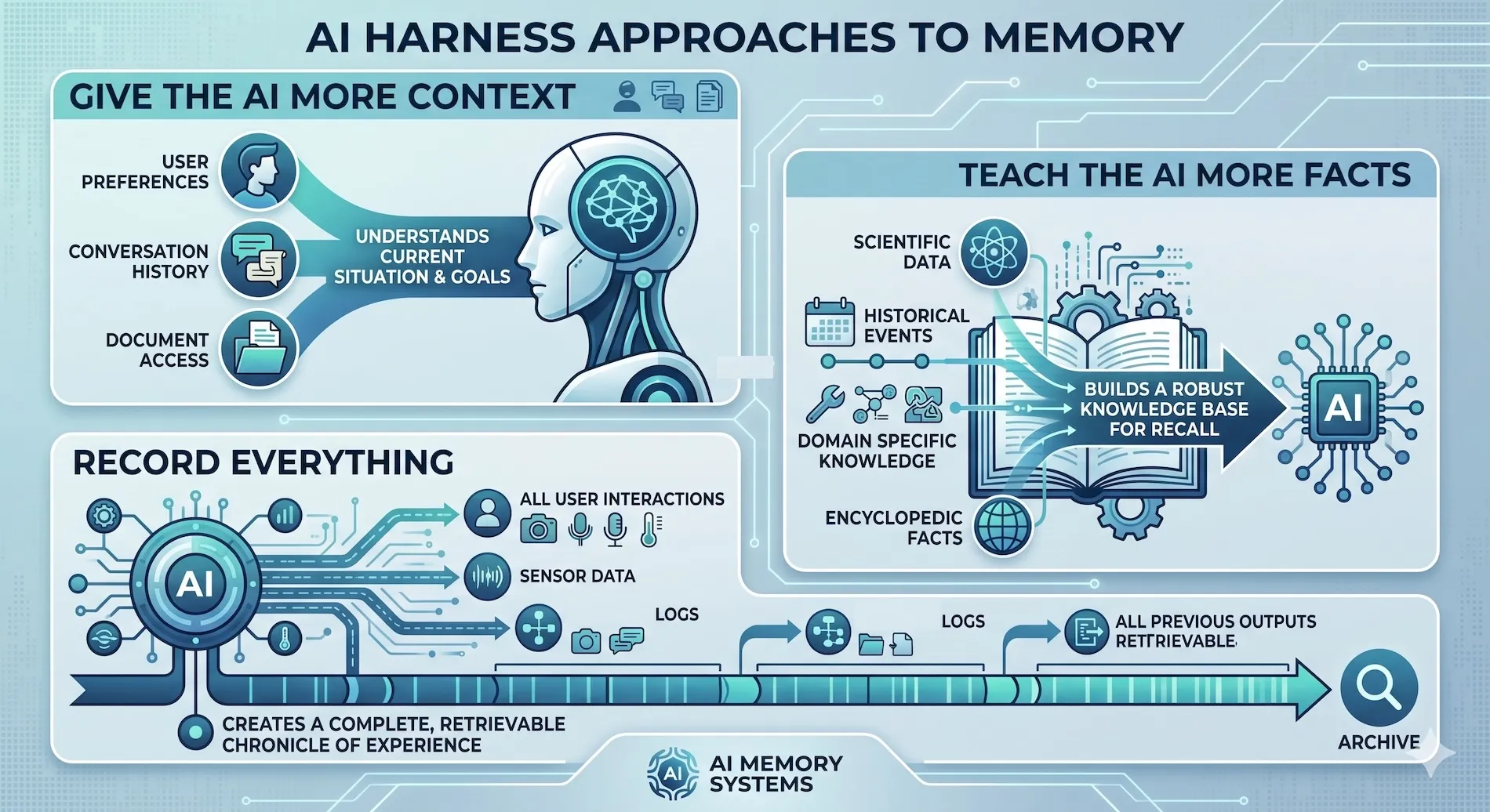
The Three Approaches to AI Memory Today
Most products in this space fall into one of three categories.
1. Give the AI More Context
GitHub Copilot, Cursor, Claude Code, and Windsurf primarily focus on maximizing the amount of context available to the model during a coding session. Custom instructions, rules, chat history, project files, documentation, and retrieved snippets are combined into a large working context window.
This works remarkably well for short and medium-duration tasks. The model can reason over substantial amounts of information and maintain momentum across a session. The challenge appears as projects grow.
As more information accumulates, relevance becomes the bottleneck. The information exists, but both humans and AI struggle to determine which parts matter for the current task, and which is just useless accumulation. Teams often describe this phenomenon as “context bloat”.
It is telling that this category has already tried to grow past pure context. Cursor shipped a project-level “Memories” feature in 2025 to automatically store facts gleaned from conversations, then removed it again and pointed users back to hand-written Rules. Accumulating more facts, on its own, did not solve the problem.
2. Teach the AI More Facts
Memory layers like Mem0 and agent runtimes like Letta (formerly MemGPT), along with RAG-based frameworks, focus on extracting facts, summaries, entities, and relationships from conversations and interactions. Instead of storing entire conversations, they attempt to identify durable information worth remembering, things like architectural facts, user preferences, and even long-term agent knowledge.
This represents a major improvement over simple conversation history because the memory becomes searchable and structured. The system becomes better at answering “What do we know?” but not necessarily “Why did we decide this?”. It does not capture what options were considered at the time, what trade-offs were weighed, or whether a choice was a deliberate decision or just a temporary workaround. The primary unit of memory remains a fact, summary, or relationship rather than the reasoning process that produced it.
For software engineering, this works surprisingly well for documentation, API references, architecture documents, and runbooks. Their challenge is preserving the reasoning behind how that knowledge evolved over time.
The most advanced systems in this category go further still. Zep’s Graphiti, for example, stores knowledge as a temporal knowledge graph in which every fact carries a validity window — when it became true, and when it was superseded. This is genuinely powerful, and far closer to how a project actually changes than a flat vector store. But the unit of memory is still a fact. A temporal graph can record that “we use RabbitMQ” became true in March and was replaced in May. It cannot record that Kafka and SQS were the alternatives, that the deciding constraint was a small platform team, or that the change was a deliberate trade-off rather than accidental drift. The reasoning never enters the graph.
Here is a real decision, from building the very site you are reading.
A fact is: The social-card images use the IBM Plex Sans JP font.
A decision is:
Use IBM Plex Sans JP (not Noto Sans JP) for Japanese social-card images.
Alternatives considered: Noto Sans JP, Noto Sans CJK JP
Reason: Fontsource serves Noto Sans JP as a variable font that the build-time
renderer (CanvasKit) registers under the family name "Noto Sans JP Thin".
Our font list never matches that name, so every Japanese card rendered
as blank "tofu" boxes. IBM Plex Sans JP ships static weights with a
stable family name.
Constraint: CanvasKit only falls back across fonts named explicitly in the list.
Date: June 2026The code that ships only says 'IBM Plex Sans JP'. None of the reasoning above survives in it. An AI agent later asked to “use the brand’s Noto font for consistency” would switch it back, reintroduce the tofu bug, and have no way of knowing the choice was deliberate. The fact is in the code; the decision is not.
3. Record Everything
Pieces takes a different approach. Rather than focusing only on conversations or code, it captures the broader workflow surrounding software development. Code edits, copied snippets, websites visited, AI conversations, desktop activity, and development history become part of a searchable timeline.
This creates an impressive form of episodic memory.
Developers can reconstruct what happened yesterday, last week, or last month with far greater accuracy than relying on memory alone. The question Pieces answers exceptionally well is “What was I doing?”.
It is our viewpoint that software projects are ultimately shaped by decisions, not activities. Knowing the summary of a meeting is useful, but immediately knowing why a particular micro-architecture was chosen by your AI agent is often more valuable. The current state of a project is only the final snapshot of thousands of decisions. Without understanding how those decisions evolved, both humans and AI agents are forced to repeatedly rediscover the same reasoning.
The Missing Layer: Decision Memory
When we analyzed long-running software projects, we found that the most expensive mistakes rarely stemmed from lack of documentation or from a poor knowledge graph. Instead, bugs and broken features arise from forgotten decisions.
A new engineer starts a discussion about a design that was already invalidated months ago. An AI agent implements a solution that was previously rejected. Or it analyzes only the present “facts” and surrounding code, and decides to fix the bug at a superficial level, even though 2 weeks ago another agent implemented a carefully planned utility that solves many of the issues and it only needs to be integrated.
The information often still exists somewhere inside git history, pull requests, issue trackers, Slack conversations, or AI chat histories. The problem is that the decision itself was never captured as a first-class object.
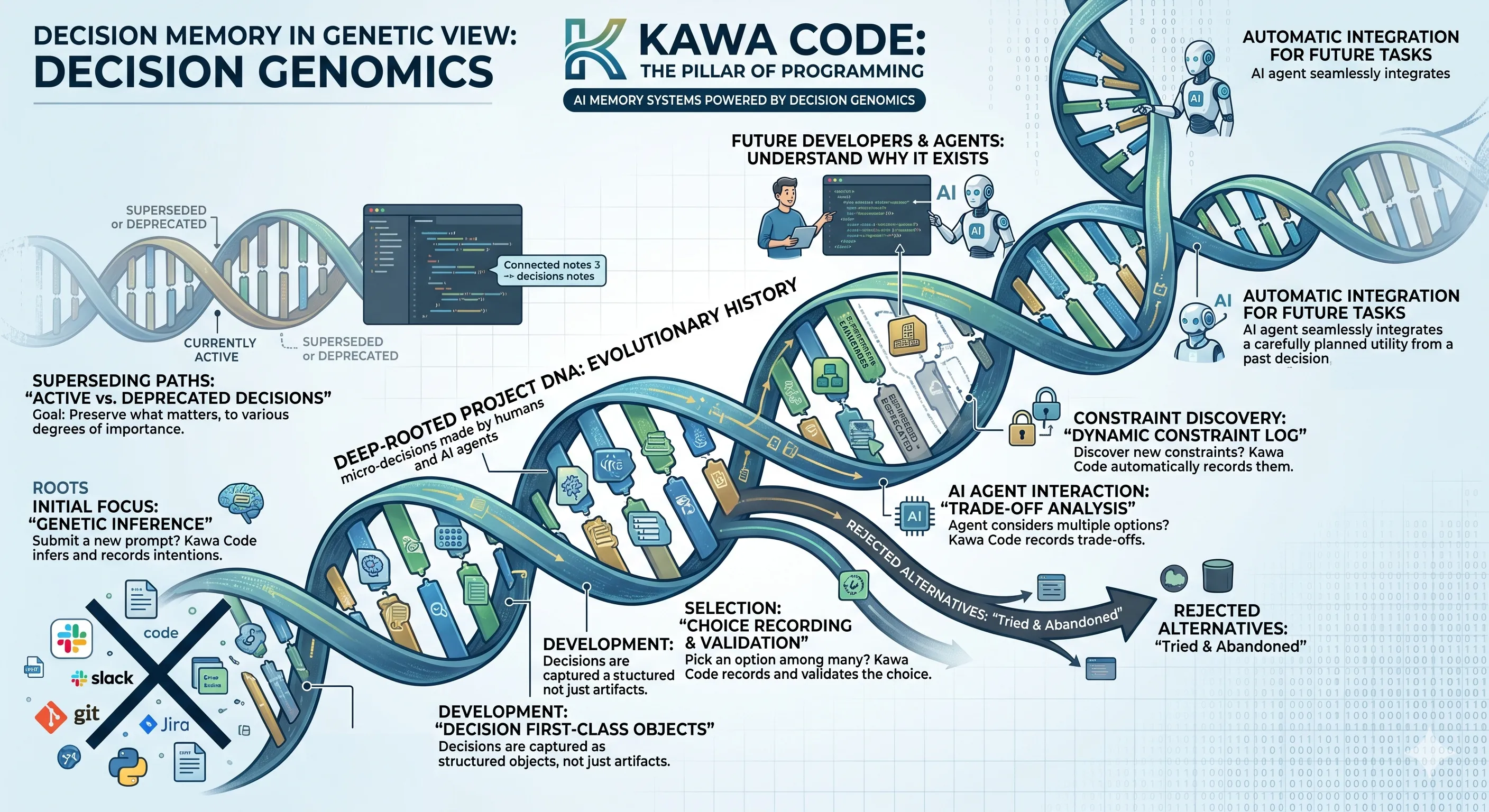
Kawa Code and Decision Genomics
As AI coding workflows mature, many organizations are discovering that the problem is not the inability to store information. The problem is deciding which information deserves to be included.
Kawa Code was built around what we believe is the most valuable artifact in software development: the graph of all micro-decisions made by humans and AI agents.
Rather than focusing exclusively on accumulating every little thing you do, Kawa Code automatically extracts and structures the evolution of decisions made by all participants to a project, human and AI alike.
- You submit a new prompt? Kawa Code infers your intentions and records them.
- You pick an option among many? Kawa Code records and validates that decision.
- The agent considers multiple options and picks one? Kawa Code records the trade-offs considered.
- You or your agent discover new constraints? Kawa Code automatically records them for the future.
- You tried something and abandoned it? Kawa Code records it as a rejected alternative.
- You discuss with your AI the pros and cons of an architecture? Kawa Code records that architectural rationale.
These decisions are attached to the code they influence, survive across branches and rebases, and evolve as projects evolve. Older decisions can be superseded or deprecated instead of lingering as permanently-active context the way an undated fact in a vector store does. The goal here is not to preserve everything, but to preserve what matters, to various degrees of importance, and automatically use those pieces of information for each task an agent works on.
If that sounds like Architectural Decision Records, or a hand-maintained “memory bank” of markdown files like the ones popularized by Cline, the difference is capture. ADRs and memory banks are written by hand, drift out of date the moment the code moves on, and sit separately from the code they describe. Kawa Code captures these decisions automatically as you and your agent work, anchors them to the exact lines they govern, and carries them across branches and rebases — so no one has to remember to write them down, and they cannot quietly go stale.
We call this approach Decision Genomics. Just as DNA preserves the evolutionary history of an organism, decision graphs preserve the evolutionary history of a software project. Future developers and AI agents can understand not only what exists today, but why it exists.
Most memory today is private and tool-locked. Cursor’s memory lives inside Cursor; open Claude Code or another agent on the same machine and it is gone, and a teammate’s editor never sees what you discovered last week unless you write it down by hand. Kawa Code is the opposite: the decision graph is shared across humans and AI agents, and across editors — VS Code, JetBrains, Emacs, and any MCP-capable agent such as Claude Code, Cursor, or Windsurf — creating one common reasoning layer for the entire team rather than a private cache per tool.
Because that reasoning is shared while the work is still in progress, Kawa Code can also see when two teammates are changing the same code before either has committed, and surface the overlap directly in the editor — avoiding conflicts before merge time instead of discovering them after. This pre-commit intersection detection is patented (JP 7150002).
| Approach | Examples | The question it answers |
|---|---|---|
| Give the AI more context | Cursor, Claude Code, Windsurf | "What information might matter?" |
| Teach the AI more facts | Mem0, Letta | "What do we know?" |
| Record everything | Pieces | "What was I doing?" |
| Remember WHY | Kawa Code | "Why did we decide this?" |
This has an important side effect. By focusing on decisions, constraints, and rationale instead of entire histories, Kawa Code can often provide dramatically smaller contexts to AI assistants. Rather than replaying months of conversations and documentation, the system surfaces only the reasoning most relevant to the current task. For organizations operating dozens or hundreds of AI agents, this can translate directly into lower inference costs and higher throughput.
As AI adoption grows and token costs become a meaningful operational expense, we believe the future of AI memory will be measured not only by recall quality, but by compression quality: how effectively a system can preserve the reasoning behind a project while minimizing the amount of information that must be sent to the model.
Beyond Memory
The future challenge for AI-assisted software development is unlikely to be code generation. Models are already becoming exceptionally capable at producing code.
The harder problem is maintaining coherence across thousands of decisions made by humans and AI over months or years. Memory systems are an important part of that future.
We believe the next generation of developer tooling will be defined by how effectively it captures, evolves, and surfaces the decisions that shape a project.
Not more memory. Better memory.